Linear models#
Fitting a function \(f(.)\) to datapoints \(y_i=f(x_i)\) under some error function. Based on the estimated function and error, we have the following types of regression.
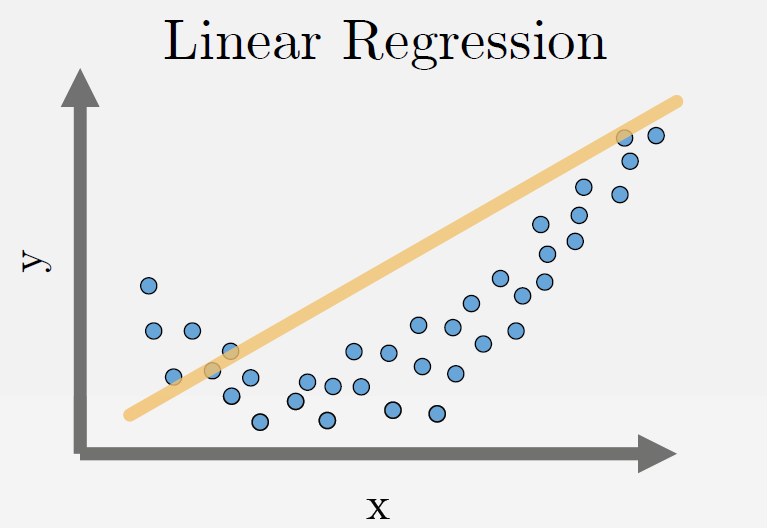
Linear Regression#
Fits a line minimizing the sum of mean-squared error for each datapoint.
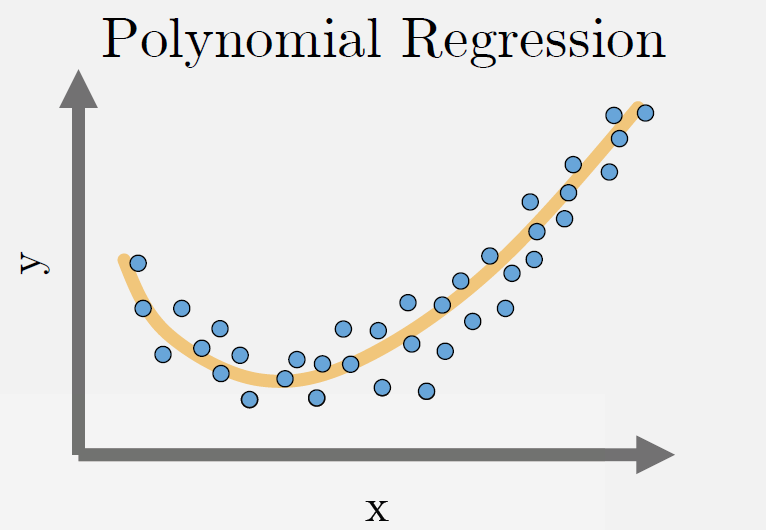
Polynomial Regression#
Fits a polynomial of order \(k\) (\(k+1\) unknowns) minimizing the sum of mean-squared error for each datapoint.
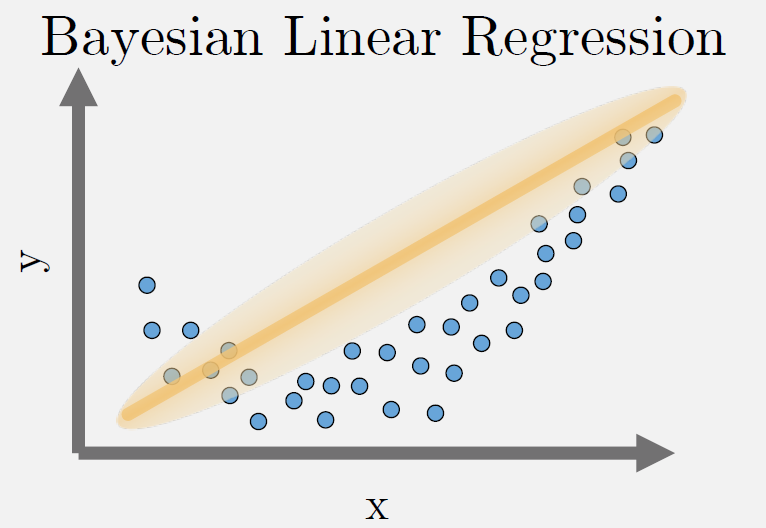
Bayesian Regression#
For each datapoint, fits a gaussian distribution by minimizing the mean-squared error. As the number of data points xi increases, it converges to point estimates i.e. \(n \rightarrow \infty, \sigma^2 \rightarrow 0\)
where \(\mathcal{N}(\mu, \sigma^2)\) is a Gaussian distribution with mean \(\mu\) and variance \(\sigma^2\)
Ridge Regression#
Can fit either a line, or polynomial minimizing the sum of mean-squared error for each datapoint and the weighted L2 norm of the function parameters beta.
LASSO Regression#
Can fit either a line, or polynomial minimizing the the sum of mean-squared error for each datapoint and the weighted L1 norm of the function parameters beta.
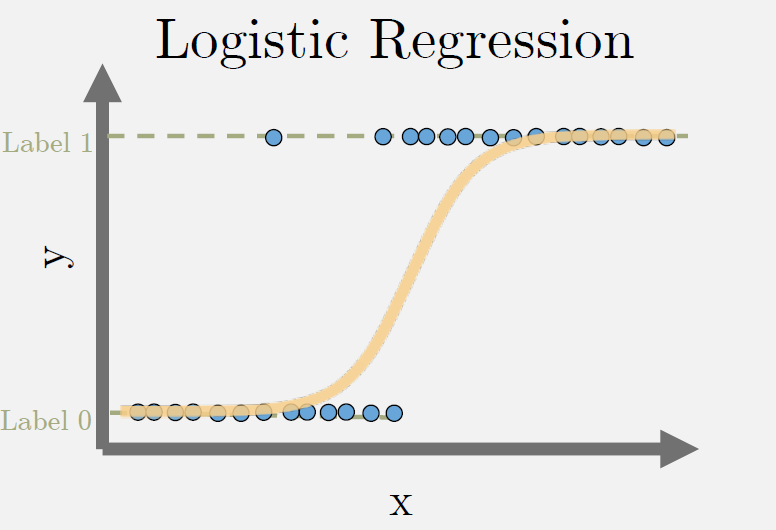
Logistic Regression#
Can fit either a line, or polynomial with sigmoid activation minimizing the binary cross-entropy loss for each datapoint. The labels y are binary class labels.